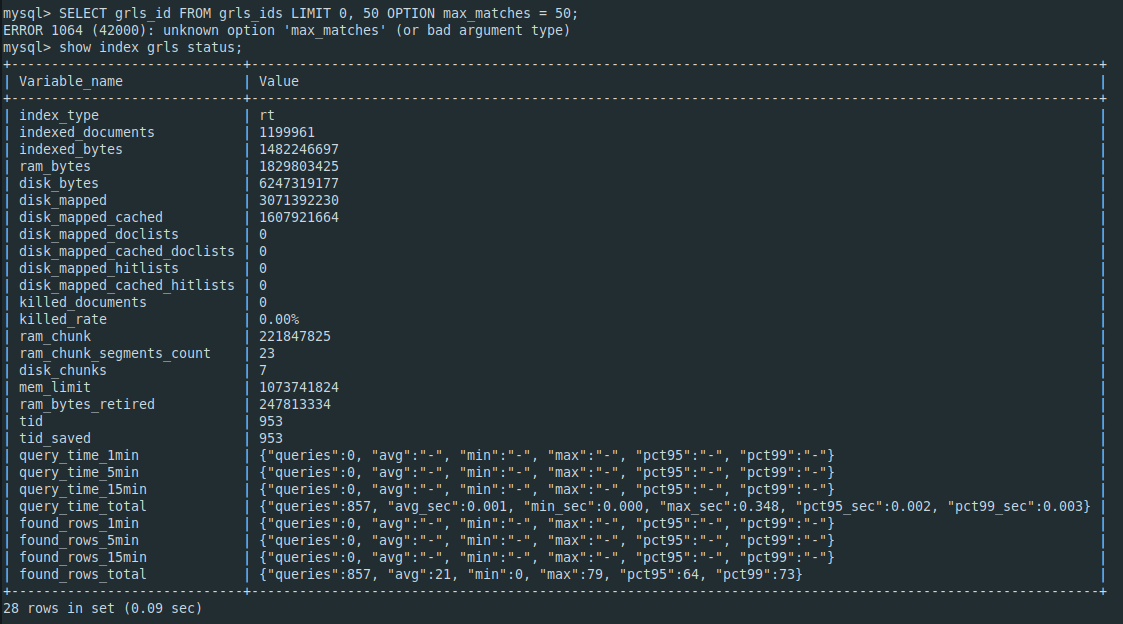
We have two nodes in cluster. After creating a cluster and adding empty indexes to it, everything works well. However, after one index is filled, we get the following error:
mysql> SELECT un_sku_id FROM sku OPTION max_matches = 1; ERROR 1064 (42000): unknown option ‘max_matches’ (or bad argument type)
The error occurs only on the first node. The second node returns proper results for this query. It happens when using version 3.5.2. With version 3.5.0 everything works properly.
Can you make a step-by-step scenario that reproduces this and open a ticket on github? I just tried on our replication course (Manticore tables replication) and I can’t reproduce it.
Unfortunately, the only way to reproduce it is to provide you SQL dump with ~400.000 insert queries, but this is sensitive data. We have no idea after which of these queries the problem occurs. The only thing we know is that the problem is not reproduced on an empty index.
It’s OK for us to stay at 3.5.0, if there is no other way to investigate the issue.
If you have debugger onboard and installed debug symbols package for release, you can provide backtrace to us.
That is most probably from searchdsql.cpp line 532. If you set breakpoint there (after attaching to running instance with gdb), and then reproduce the error (so that breakpoint will be hit), you can issue command ‘where’ and attach the output (of course, you can check if that output doesn’t contains your sensitive data).
Unfortunately, we do not have the ability to provide this information at the moment as long as we downgraded to version 3.5.0. If we upgrade Manticore in the future and experience the same problem, we will provide you with the necessary information then.
I’m not sure in which moment the problem occurs. When indexes are created from scratch and added to cluster, everything works well. The problem occurs suddenly when indexes are filling.
We use the same binary as you mentioned.
The problem does not occur with version 3.5.0. Only with 3.5.2 and higher.
there was a fix at dc7285890c8816d53b19f791c25f37bce4eac1f1 of reduce \ shift at SphinxQL parser at option - could you try to use recent dev version of daemon and post here what package will you use?
I will provide step by step debug instruction for that package as GDB commands will use source code line numbers.
I have managed to reproduce the problem at Server version: 3.5.3 4367c82a@201116 release git branch HEAD (no branch). There were the following steps:
I created 12 RT indexes on a server, created a cluster and added these indexes to the cluster.
I added two additional nodes to the cluster.
Then I filled all indexes in the cluster.
After this I stopped Manticore on the 3rd node and cleaned data and binlog folders. Then I restarted the server.
After the server is restarted, I joined the 3rd node to the cluster again (as long as it became a vanilla Manticore instance with no indexes).
The node joined to the cluster properly, however the problem appeared again on this node. On the 1st and 2nd nodes the problem is not reproduce, the query is executed without any errors there.