Hi,
I’m new to Manticore and I’m working on some research to find out if Manticore features will work for my project.
Basically, what I’m looking for is
- can I index the text between xml/html tags
- can I index certain custom attributes on those xml/html tags
- can I do a full text match query to fetch results based on data indexed
- can I filter using the indexed data from html_index_attrs
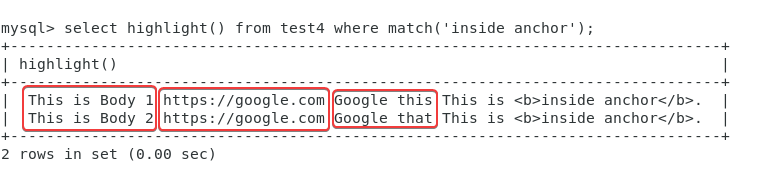
I was able to get the first three working. However, I’m unable to find any documentation as to how I can filter results using the attributes listed under “html_index_attrs”.
For example:
CREATE TABLE test4(int_id int, doc_id int, content text, name string, title text indexed) index_zones = ‘html, body, a’ html_index_attrs = ‘a=href,title; body=title’ html_strip = ‘1’ morphology = ‘libstemmer_en, libstemmer_es’;
insert into test4(int_id,doc_id,content,name,title) values (2407481, 96401, ‘<html><body title="This is Body 1"><a href="https://google.com" title="Google this">This is inside anchor.</a></body></html>', 'Google this name', 'Google this title’);
insert into test4(int_id,doc_id,content,name,title) values (2407482, 96402, ‘<html><body title="This is Body 2"><a href="https://google.com" title="Google that">This is inside anchor.</a></body></html>', 'Google that name', 'Google that title’);
insert into test4(int_id,doc_id,content,name,title) values (2407483, 96403, ‘<html><body title="This is Body 2"><a href="https://google.com" title="Google this and that">This is inside anchor.</a></body></html>', 'Google this and that name', 'Google this and that title’);
As per above, what query syntax do I use to fetch me only those rows that have a body title of “This is Body 2”?