Hi Manticore team,
I’m encountering an issue with inconsistent relevance scores across my replicated cluster setup and was hoping to get some insight from the community.
Setup:
Manticore Search cluster with 3 nodes
Each node has an identical copy of the data (same ad_complete table around 6,500,000 rows)
Custom ranker in use: ranker=expr('sum((4*lcs + 10*wlccs + (min_hit_pos==1) + word_count + 2*exact_hit + 25*tf_idf) * user_weight) * 100 + 10*bm25 + ...')
Here is ad_complete table definition:
CREATE TABLE ad_complete (
id bigint,
name text indexed,
description text indexed,
category_group_name text indexed,
condition_tag text indexed,
price_text_tag text indexed,
ad_tags text indexed,
car_fuel_type_tag text indexed,
car_body_type_tag text indexed,
car_gearbox_tag text indexed,
car_drive_tag text indexed,
car_model_tag text indexed,
vehicle_drive_tag text indexed,
vehicle_tags text indexed,
favorite_user_ids text indexed,
has_photo integer,
is_top integer,
is_top_search integer,
is_priority integer,
is_highlighted integer,
is_top_gold integer,
vehicle_km integer,
vehicle_make_year integer,
vehicle_cc integer,
vehicle_power integer,
vehicle_power_h integer,
view_count integer,
is_currency_eur integer,
is_currency_rsd integer,
location_id integer,
courier_delivery integer,
local_pickup integer,
posted integer,
pre_sort integer,
posted_sort integer,
price_sort integer,
price_rsd float,
price_eur float,
location_lon float,
location_lat float,
last_updated_ts integer
) wordforms = ‘/etc/manticoresearch/wordforms.txt’
charset_table = ‘0..9, A..Z->a..z, _, a..z, U+017E->z, U+017D->z, U+0161->s, U+0160->s, U+0107->c, U+0106->c, U+010C->c, U+010D->c, U+0111->d, U+0110->d, U+0430->a, U+0431->b, U+0432->v, U+0433->g, U+0434->d, U+0452->d, U+0435->e, U+0436->z, U+0437->z, U+0438->i, U+0458->j, U+043A->k, U+043B->l, U+043C->m, U+043D->n, U+043E->o, U+043F->p, U+0440->r, U+0441->s, U+0442->t, U+045B->c, U+0443->u, U+0444->f, U+0445->h, U+0446->c, U+0447->c, U+045F->U+01C6, U+0448->s, U+0410->a, U+0411->b, U+0412->v, U+0413->g, U+0414->d, U+0402->d, U+0415->e, U+0416->z, U+0417->z, U+0418->i, U+0419->j, U+041A->k, U+041B->l, U+041C->m, U+041D->n, U+041E->o, U+041F->p, U+0420->r, U+0421->s, U+0422->t, U+040B->c, U+0423->u, U+0424->f, U+0425->h, U+0426->c, U+0427->c, U+040F->U+01C4, U+0428->s’
min_prefix_len = ‘3’
html_strip = ‘1’
blend_chars = ‘+, -, &, U+23’
prefix_fields = ‘name,description’
expand_keywords = ‘1’
index_exact_words = ‘1’
;
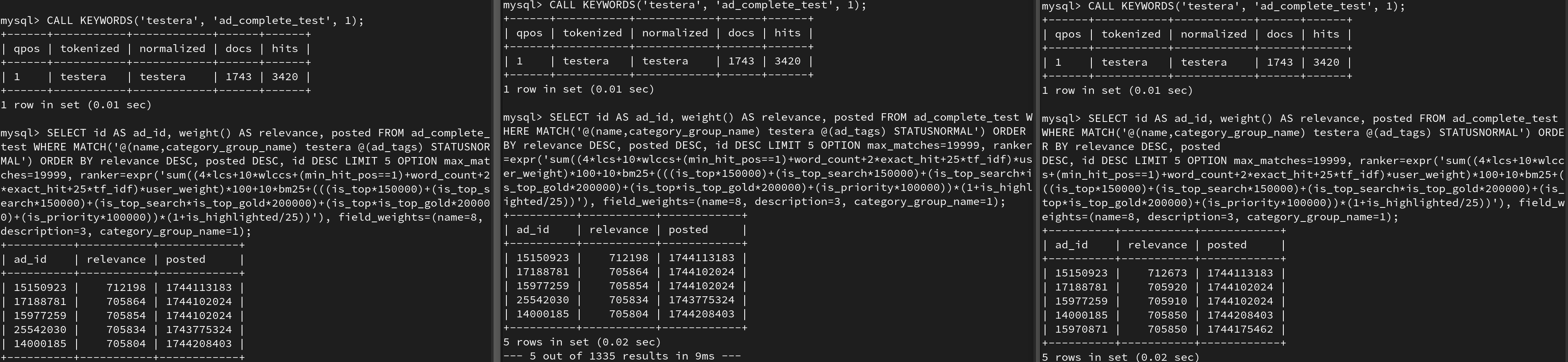
Problem: When I run the same search query on different nodes against the same document set, I get different relevance scores for identical documents.
The data is completely replicated, and I’ve verified content is the same. Although, when i run
CALL KEYWORDS(‘some_keyword’, ‘ad_complete’, 1);
i get different results for docs and hits on each server.
Question: What could cause the custom ranker to produce inconsistent results across nodes in a replicated cluster? Is there any part of the ranking pipeline that could introduce non-determinism?
Thanks in advance for your help!
Best regards,
Dimitrije Marinković