We recently upgraded our Sphinx 2.2.11 installation to the latest Manticore release and it works so far pretty well. Except one thing: Running Manticore several days, it starts to collect RAM very slowy. I really don’t know, why and what we might got wrong here. I wasn’t brave enough yet, to let it run and see, if there might be a threshold, so after five or six days or so, I restarted the searchd.
What could be the reason for Manticore to stockpile memory? We have only one RT index. It status looks like this:
+-------------------+--------------------------------------------------------------------------------------------------------------+
| Variable_name | Value |
+-------------------+--------------------------------------------------------------------------------------------------------------+
| index_type | rt |
| indexed_documents | 6415138 |
| indexed_bytes | 30079168673 |
| ram_bytes | 1369425609 |
| disk_bytes | 3557370344 |
| ram_chunk | 241625732 |
| disk_chunks | 1 |
| mem_limit | 1073741824 |
| query_time_1min | {"queries":86, "avg_sec":0.068, "min_sec":0.005, "max_sec":0.756, "pct95_sec":0.311, "pct99_sec":0.311} |
| query_time_5min | {"queries":483, "avg_sec":0.080, "min_sec":0.002, "max_sec":0.756, "pct95_sec":0.251, "pct99_sec":0.321} |
| query_time_15min | {"queries":1684, "avg_sec":0.089, "min_sec":0.002, "max_sec":0.824, "pct95_sec":0.404, "pct99_sec":0.640} |
| query_time_total | {"queries":197712, "avg_sec":0.082, "min_sec":0.001, "max_sec":19.826, "pct95_sec":0.247, "pct99_sec":0.496} |
| found_rows_1min | {"queries":86, "avg":20, "min":1, "max":679, "pct95":149, "pct99":149} |
| found_rows_5min | {"queries":483, "avg":36, "min":0, "max":4109, "pct95":235, "pct99":398} |
| found_rows_15min | {"queries":1684, "avg":22, "min":0, "max":4109, "pct95":165, "pct99":579} |
| found_rows_total | {"queries":197712, "avg":33, "min":0, "max":71263, "pct95":47, "pct99":447} |
+-------------------+--------------------------------------------------------------------------------------------------------------+
This is the searchd config:
searchd
{
# IP address to bind on
# optional, default is 0.0.0.0 (ie. listen on all interfaces)
#
# address = 127.0.0.1
# address = 192.168.0.1
# searchd TCP port number
# mandatory, default is 3312
listen = 127.0.0.1:9306:mysql41
# log file, searchd run info is logged here
# optional, default is 'searchd.log'
log = /var/log/sphinx/searchd.log
# client read timeout, seconds
# optional, default is 5
read_timeout = 5
# PID file, searchd process ID file name
# mandatory
pid_file = /var/log/sphinx/searchd.pid
# whether to unlink .old index copies on succesful rotation.
# optional, default is 1 (do unlink)
unlink_old = 1
binlog_path = /var/data
collation_libc_locale = de_DE.utf8
expansion_limit = 16
attr_flush_period = 1800 # persist updates to disk every 30 minutes
}
And here you can see the memory ramps…
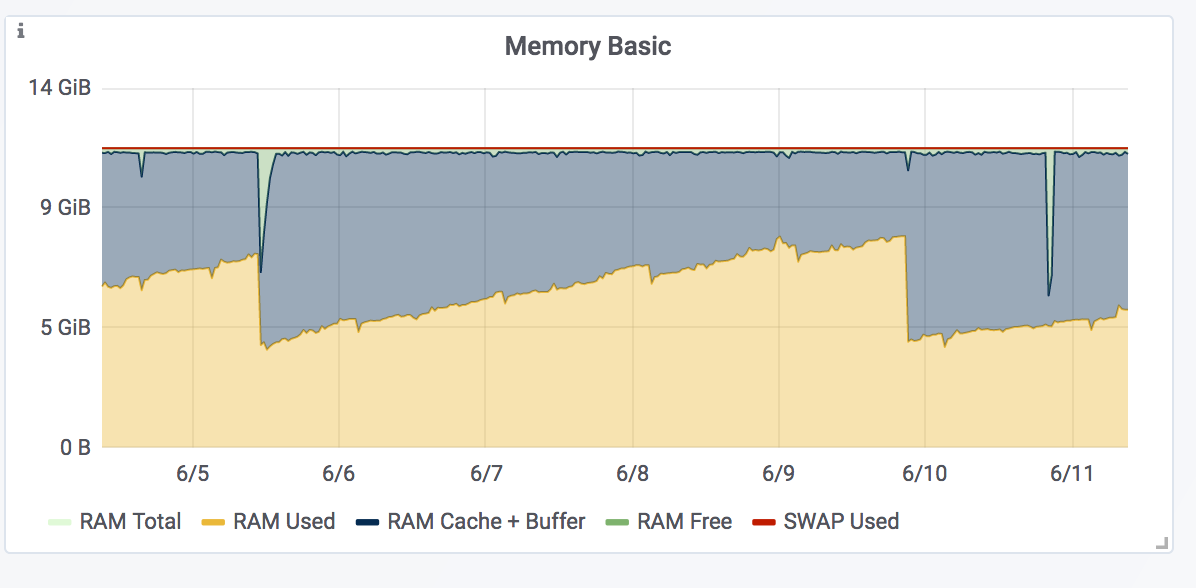
The original sphinx was pretty constant in memory usage and so im curious whats going on here…
