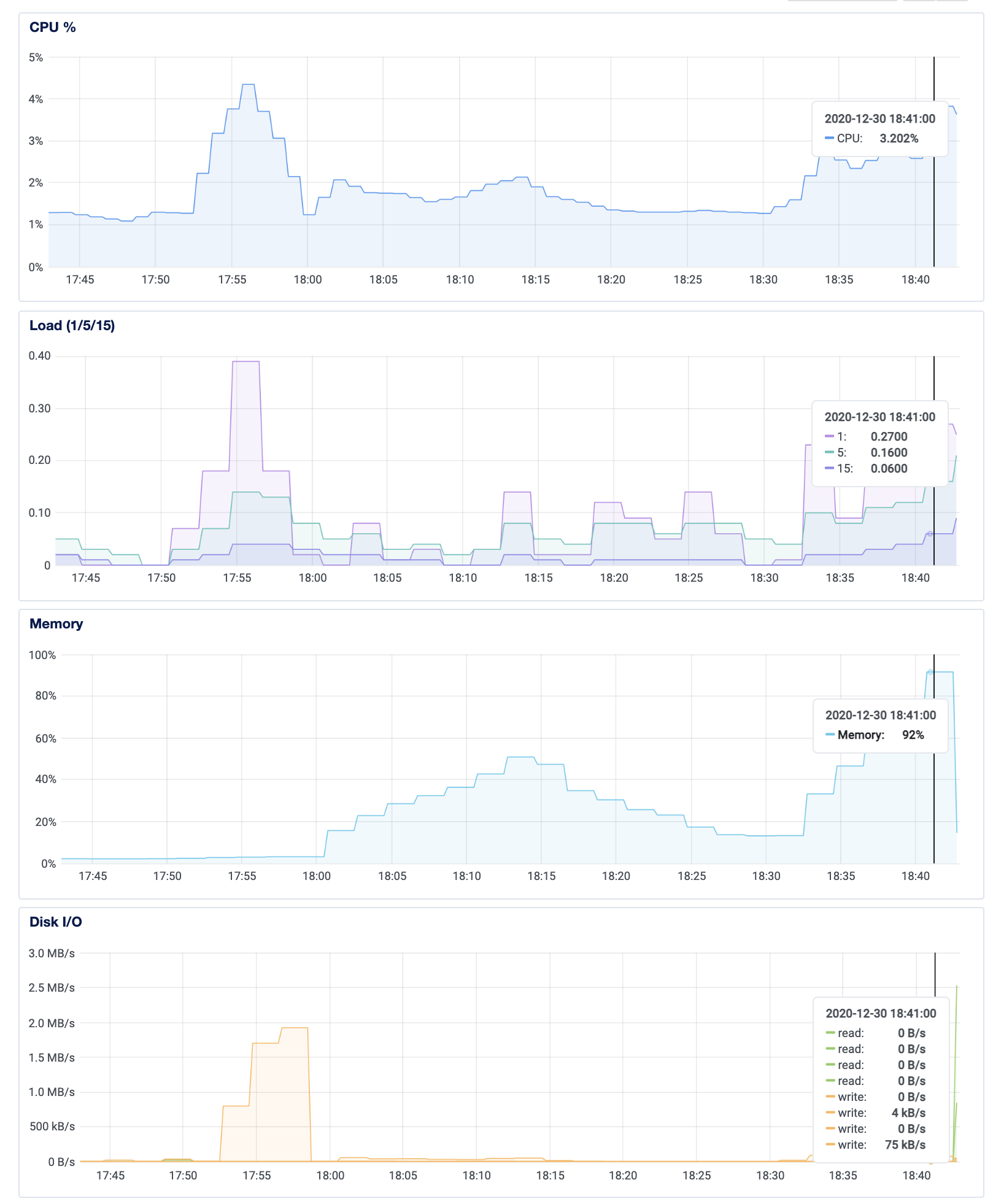
I am trying to get my Manticore Cluster work properly on Kubernetes but I am facing memory usage issues which lead to the pod’s systematic eviction / crashloop backoff.
I have two nodes, with 4 CPUs and 16 Gi RAM each, running one manticore container each. I have set up Requests and Limits for each of them at 80% full potential, but my pods keep being OOMkilled by Kubernetes system (Out Of Memory).
I am using RealTime index and each time I do some “REPLACE INTO” queries, the memory keeps on increasing. I have managed to monitor this with this command :
kubectl top pod manticore-6446***6c-6bcd8
NAME CPU(cores) MEMORY(bytes)
manticore-64466f86c-6bcd8 1m 3429Mi
CPU is keeping with low values but memory can’t stop increasing and when it reaches my pod’s limit, it gets destroyed, again and again. Is there a way to “cap” memory usage or to flush automatically to disk before the pod gets destroyed?
Here is the result of a “kubectl top” command after a few minutes (around 30 minutes) of quite intensive “REPLACE INTOs”. I’ve upgraded the servers to 32 GB to see if it helps.
kubectl top pod manticore-5467cb5c74-4j7nz
NAME CPU(cores) MEMORY(bytes)
manticore-5467cb5c74-4j7nz 1m 276Mi
kubectl top pod manticore-5467cb5c74-4j7nz
NAME CPU(cores) MEMORY(bytes)
manticore-5467cb5c74-4j7nz 21m 7925Mi
kubectl top pod manticore-5467cb5c74-4j7nz
NAME CPU(cores) MEMORY(bytes)
manticore-5467cb5c74-4j7nz 18m 8677Mi
kubectl top pod manticore-5467cb5c74-4j7nz
NAME CPU(cores) MEMORY(bytes)
manticore-5467cb5c74-4j7nz 31m 11463Mi
kubectl top pod manticore-5467cb5c74-4j7nz
NAME CPU(cores) MEMORY(bytes)
manticore-5467cb5c74-4j7nz 27m 13238Mi
kubectl top pod manticore-5467cb5c74-4j7nz
NAME CPU(cores) MEMORY(bytes)
manticore-5467cb5c74-4j7nz 1m 16226Mi
After 30 minutes, memory usage has hit a maximum of around 16Gi and began to lower.
kubectl top pod manticore-5467cb5c74-4j7nz
NAME CPU(cores) MEMORY(bytes)
manticore-5467cb5c74-4j7nz 2m 9892Mi
kubectl top pod manticore-5467cb5c74-4j7nz
NAME CPU(cores) MEMORY(bytes)
manticore-5467cb5c74-4j7nz 5m 8683Mi
But it went up again and it finally crashed …
kubectl top pod manticore-5467cb5c74-4j7nz
NAME CPU(cores) MEMORY(bytes)
manticore-5467cb5c74-4j7nz 77m 11814Mi
kubectl top pod manticore-5467cb5c74-4j7nz
NAME CPU(cores) MEMORY(bytes)
manticore-5467cb5c74-4j7nz 1m 20172Mi
kubectl top pod manticore-5467cb5c74-4j7nz
NAME CPU(cores) MEMORY(bytes)
manticore-5467cb5c74-4j7nz 110m 26104Mi
By chance I’ve attached a PersistentVolumeClaim, so it restarts from where it was, but it creates a downtime during which it can’t be updated.