[Sun May 12 22:11:25.413 2019] [29143] rt: index rt1: ramchunk saved ok (mode=periodic, last TID=3977609, current TID=3978612, ram=360.194 Mb, time delta=36005 sec, took=1.199 sec)
[Mon May 13 08:11:29.734 2019] [29143] rt: index rt1: ramchunk saved ok (mode=periodic, last TID=3978612, current TID=3979917, ram=361.493 Mb, time delta=36004 sec, took=1.139 sec)
[Mon May 13 18:11:35.374 2019] [29143] rt: index rt1: ramchunk saved ok (mode=periodic, last TID=3979917, current TID=4028011, ram=418.112 Mb, time delta=36005 sec, took=2.347 sec)
[Tue May 14 08:55:23.916 2019] [29143] rt: index rt1: ramchunk saved ok (mode=periodic, last TID=4073490, current TID=4146798, ram=177.408 Mb, time delta=36001 sec, took=0.254 sec)
[Tue May 14 18:55:29.650 2019] [29143] rt: index rt1: ramchunk saved ok (mode=periodic, last TID=4146798, current TID=4214409, ram=312.449 Mb, time delta=36005 sec, took=1.096 sec)
[Wed May 15 04:55:31.116 2019] [29143] rt: index rt1: ramchunk saved ok (mode=periodic, last TID=4214409, current TID=4216137, ram=315.077 Mb, time delta=36001 sec, took=1.097 sec)
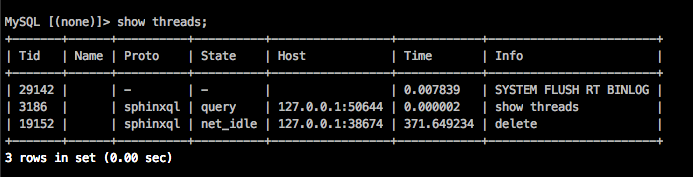
when you might connect to your daemon again and issue show threads to see that delete got finished or still running. Or increase timeout value at your client.
There is no max_query_time option at DELETE as it is a single transaction and should be applied or rolled back and not taking into account time.
You also might issue show index rt1 status and check that index has sane amount of disk chunks and maybe optimize index in case it has large count of disk chunks to reduce duplicated data.
net_Idle is state show that after command finished and send data back to client handler wait for next MySQL command from client or MySQL MYSQL_COM_QUIT message or socket got break on client terminate or timeout happens.
You could also restart your daemon with --logdebugv to log any network activity into searchd.log then provide that log. However that should be done at test server as at production that slow down daemon and make log file very large quickly.