Приветствую, коллеги!
Очень долго немогу решить задачку - а именно:
К примеру я хочу создать правило для окончаний где требуется ‘с’ заменить на ‘сы’ итп. То есть, чтобы слова ‘сброс’ и ‘сбросы’ , ‘трус’ и ‘трусы’ итп. выводили одинаковые результаты. То есть - смысл объединение слов в множественные и одиночные числа. На моём языке нет готовых решений…
Можете ли Вы набросать внятный примерчик - как это сделать, так сказать, где то место где копать ?
Коллеги, подключайтсь - кто что знает але слышал через стенку…
Дорогие коллеги, ежели не очень утомительно - то не могли бы вы набросать примеров как и где это regexp_filter реализовать?
То есть - это нужно использовать где - в config к конкретному индексу але в запросе к бд как то новую ячейку добавляют…?
Смотрите: задача создать окончания равными по значению к примеру ‘dog’ и ‘dogs’ или ‘category’ и ‘categories’… где в последнем случае нужно как-то объединить окончания ‘y’ и ‘ies’ а в первом ’ g’ с ‘gs’. Пример с документации с 13inch как то невзашол ибо не для средних умов создан…
–
1.# index '13"' as '13inch'
regexp_filter = \b(\d+)\" => \1inch
2.# index 'blue' or 'red' as 'color'
regexp_filter = (blue|red) => color
Допустим как эти примеры можно превратить в правило - чтобы не только на дюйми, синий, красный, ну то есть использовать абстрактно, так сказать, применять ко всему, что имеет окончание допустим ‘g’ или 'у ’ …
Я вполне серьёзно. Я полагаю что это регулярные выражения,типа элементы языка сопоставимые с текстом. Так кто могит знать что там в этом вашем regexp_filter…
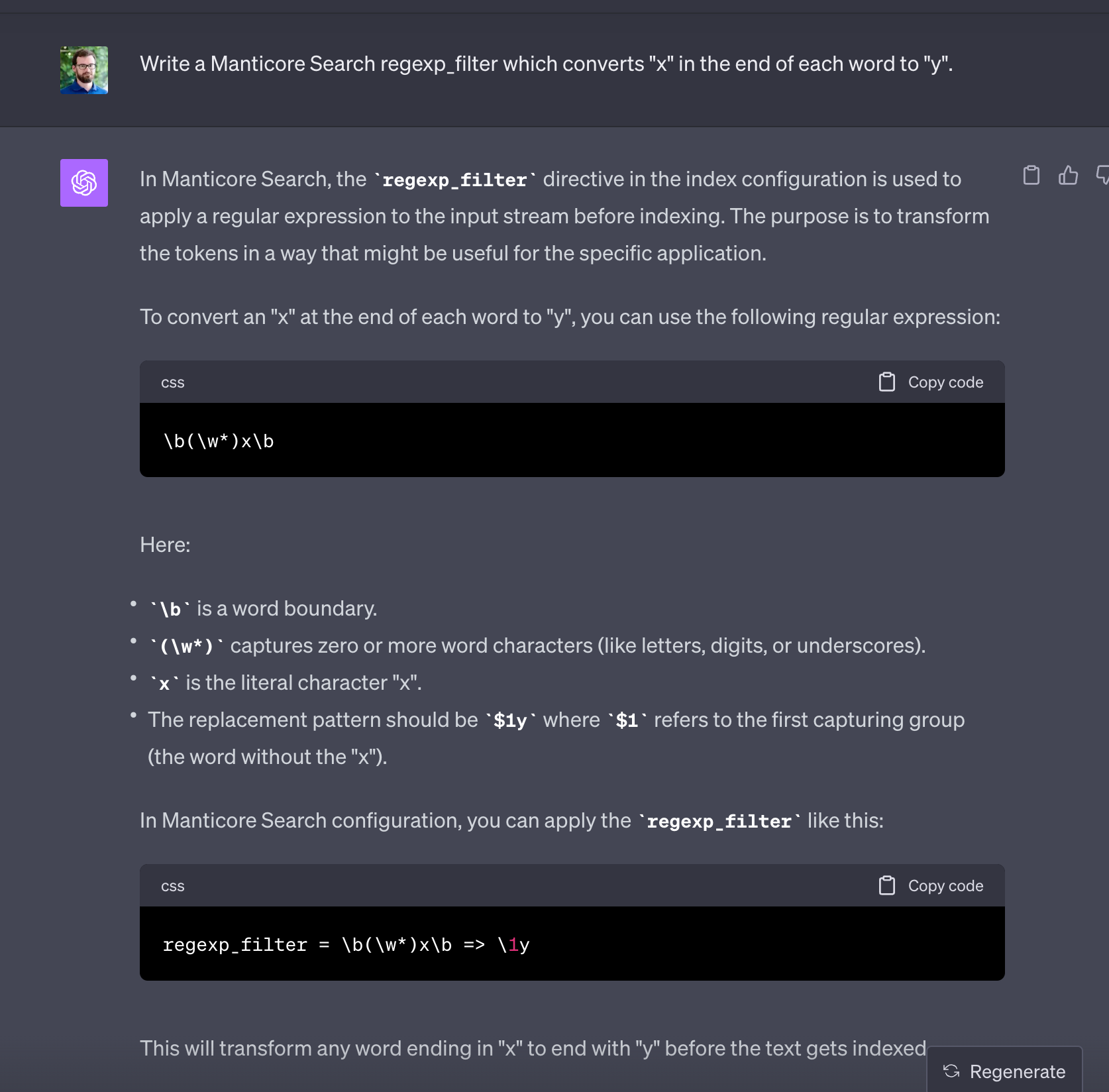
Спасибо! Вы знаете - у меня жутко мало времени чтобы всё, всё буквально выучить. Я полагаю, что Вы в теме… Может Вы могли бы накидать простую конструкцию как с помощью regexp_filter окончаниях слов просто букву ‘x’ сопоставить с ‘y’ . Это всё что мне нужно.